
15 December 2014
Follow @hankeTL;DR: The CocoaPods search engine is not web scale, but instead tailored to our needs. Here's why and how.
First let's look at some numbers... Currently, the CocoaPods search engine indexes 7378 pods. From these pods, it indexes name, author, version, dependencies, platform, summary, and synthesized tags.
On average, people search 13 times per minute, more during the week, less on weekends (switch to the Month view to see that). The occasional spike is roughly ten times that, so about twice per second. These spikes are not visible on the status page, as the number of requests are averaged over five minutes. As you can see, the search engine never rests: CocoaPods are searched for at all times.
How do our users search?
Searching on cocoapods.org
CocoaPods can be searched via the Search API, so for example at http://search.cocoapods.org/api/v1/pods.flat.hash.json?query=author:tony%20author:arnold, or via cocoapods.org.
The latter, the web site front end interface, uses the former and is more interesting, so let's have a look at that:
- It is a fast as-you-type search – if you don't type for 166 ms, it sends a query to the Search API.
- The second feature I'd like to look at in more detail in the next section: showing where your query words were found and offering the most appropriate guess.
- It lets you know when it hasn't found anything, but offers helpful suggestions, such as when you search for datanotfound. To do that, it tries to split your query based on the indexed data. It also displays a tag facet cloud.
- It sorts the results by popularity, a metric orta came up with together with David Grandinetti. This is the default sorting algorithm right now, but we're working on more. Adding a new algorithm is easy and has already been done.
Other features include storing the query in the URL for easy copying, or a results addination (portmanteau of "adding" and "pagination"), or being able to select which platform the pods are filtered with.
With the search-as-you-type feature, we encountered an interesting issue: Because shorter queries yield more results, and therefore take longer, it was possible that a request made earlier could arrive after a request made later. This led to a jarring "jumping" of results.
To solve this issue, we only show results that arrive in the order we sent them. If we send requests A, B, and C, and A returns first, we show it. If then C returns, we show it too, as it arrived in order. If then B arrives after C, we discard it, as it is out of order. That neatly solves the issue of jumping results, and also ensures a very responsive feeling for a user.
But what is the second feature about?
Picky
Picky is a semantic text search engine, running on Ruby. It is fast (it uses C for the core bits), flexible (it uses Ruby for maximum flexibility), and versatile. On the other hand it does not yet offer a drop-in server, so if you need a web service, you need to write one, such as we did. We use Picky for search.cocoapods.org.
Using Picky had two main impacts: we were able to create a highly specialized search engine for pods, and we can harness the power of a semantic search engine.
So what is this semantic search you mention? If you run orta, in the top right corner you can see an "Author 5". This means that Orta has been found five times as an author. This may not be too exciting.
However, if you enter two words, or parts of words, then Picky can start guessing what you mean. For example, if you enter orta m, then Picky guesses that you meant "Author+Name" (2 results) first, and "Author" (1 result) second. The former refers to the two pods which are named "M*" and have Orta as an author. The latter refers to the Mixpanel pod which has two authors: Orta and Mixpanel (which is why the M* finds that one).
If you click one of these suggestions, then you can see that it's possible to let Picky know what you are looking for, if you already know ("author:orta name:m"). Normally you don't need it, but it can help if you have almost no idea anymore what the pod was called. For example, perhaps you still remember that the author may have been Bob or Bert, so you enter a "B". The pod almost certainly has a word with a c in it, so you add a "C". Then Picky will show you all possibilities that a query like "B* C" results in. This query is the resulting one.
To decide what combination of categories the query words are most likely in, Picky decides based on probability. However, since we also know what combinations people will most likely look for, we've told Picky what to prefer: for often occurring combinations, we've added boosts. So if your query is found in name (+3) and dependencies (-4), then it will most likely show the name results on top.
And how is it specialized for pods? For example, when indexing pod names, we give the search engine the pieces we expect will be queried for. That usually means e.g. for "TICoreDataSync", we use the whole word, split it into the two uppercase initials, and each word starting with an uppercase letter, and also the whole word without the two initials. This enables you to search for "coredata" and get the "TICoreDataSync" pod. Or you can search for "network", and get AFNetworking.
Personally, I feel very strongly about creating specialized search engines if you want to provide the best experience for your users.
Limitations
As the CocoaPods team cannot afford a server farm, but only a single server on Heroku, and a cheap shared CPU at that, we needed to be smart in designing the infrastructure. We started with a list of requirements:
- It should fit and work on a shared Heroku CPU.
- It should reindex pods using Trunk web hook calls. So if a pod is pushed to Trunk, search should know about it ASAP (in less than 30 seconds).
- It should be stable. Nobody likes not being able to search.
- It should have little downtime when restarting.
To satisfy these requirements, we started thinking about the design.
Design
From running the search engine for a few years, we knew:
- For it to be responsive, we need multiple web workers.
- Searches are generally fast.
- To handle Trunk webhook calls (similar to GitHub webhook calls), we needed a HTTP endpoint serving these.
- To index pods while searches are being made, we need it to be done in the same process (since we use the Picky memory index, the fastest option, and Redis wasn't an option with our budget).
- Indexing a pod takes almost negligible time.
- No downtime on a single Heroku CPU is impossible, because restarts cannot be avoided.
- We don't need to serve a 1000 requests a second, even though a performance-lover like me wants to. 20-30 is enough by far (1200-1800 per minute), and we should design for that.
As a result, we arrived at this design:
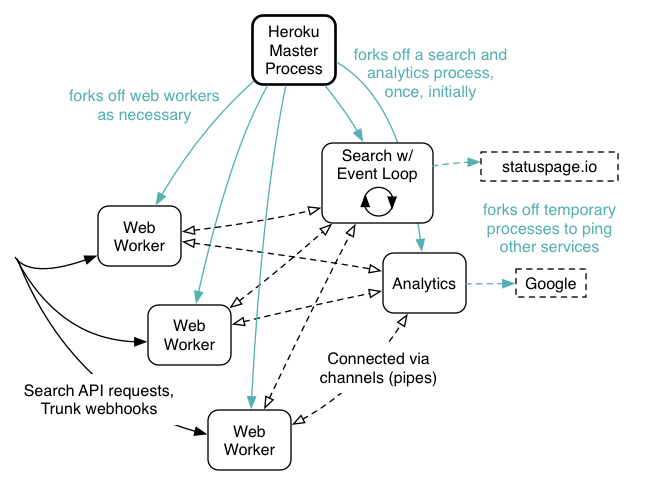
Before Unicorn spawns two web workers, we fork off an analytics and a search process. Both only load what they need after forking. Before we fork any of these, we open up channels so the web workers can communicate with the search process and the analytics process.
When a web worker forks, it chooses one of the above channels to communicate with the search engine and analytics process. Web workers are very thin – they only send the queries to the search engine process. This means any web worker can be restarted without problem, as they are relatively light.
Handling queries
If any query comes in, it is handed off to the search engine process, and also sent to the analytics process. The analytics process is only concerned with sending analytics data to Google Analytics. We need it to run in a separate process as currently we are using a synchronous library which would block the process.
The search engine process jumps straight into an event loop after forking. While looping, it checks if any requests have arrived via channels. After that, it starts indexing pods, taken from the database, a few at a time. In this way we can avoid long downtimes, as we can immediately return a few pods. A drawback of this technique is that people won't get all pods they would usually get as for example only 100 pods may yet be in the index. However, we index the pods in the order of popularity, so we fill them in from the top of the results list, so to speak. So even if the search engine is still indexing, you get relevant results.
This event loop also counts the queries for display on status.cocoapods.org. Every 30 seconds, it sends the stats to the statuspage. To not stop the event loop, we fork off these web service calls.
One issue that occurred about 9 hours after putting this live was that the search engine ran out of resources. After investigating, I had to shamefully admit that I forgot to clean up after these forks. This resulted in that single Heroku process handling on the order of 2000 child processes until it croaked, which occurred at about 9 hours after restarting. I was and am impressed at Heroku going for that long. Now, for example, we send calls to the status page every 30 seconds, remember the child process PID and clean it up again before we send off the next call. Now the search engine purrs along nicely.
Handling Trunk webhook calls
To be able to index on the fly, any of the three web workers handle Trunk webhook calls. They then inform the search engine process, also via channels, which then will reload the right pod from the Trunk DB and reindex it. This has resulted in a less than 30 second delay between you pushing to Trunk and the search engine spewing out updated results. Note that there is some browser caching of results going on, so when you try it, please clean the cache and reload.
Summary and The Future
To make a truly CocoaPod-specific search engine that would enable us to experiment and at the same time fit on a single shared Heroku instance, we used Picky, Heroku and a multiprocessing-based structure (with a single process search event loop), while still being able to serve enough results at a time.
We are currently working towards a CocoaPods search interface version 2 that will - I think - blow your minds. It will be the culmination of months (seriously!) of volunteer work and will pull together data from our many APIs to provide the snazziest pod searching interface possible.
Please leave your ideas if you have an idea to add.
